Installment 02 - Generative Adversarial Network
Introduction
This is the second and final installment for the project on conditional image generation. In this post, I present architectures that achieved much better reconstruction then autoencoders and run several experiments to test the effect of captions on the generated images.
The proposed models are variants of the generative adversarial network [7], I begin by introducing a vanilla Deep Convolutional GAN (DCGAN) [1] and then move on to the new Boundary Equilibrium GAN (BEGAN) architecture [2].
I also gave a shot at Wasserstein GAN (WGAN) [4], but unlike Louis Henri Frank’s, my results were quite disappointing, had time not been an issue it would have been interesting to take a look at the Improved training of Wasserstein GANs paper [5], but implementing it in Theano proved to be quite hard.
Implementation Detail
The first model I explored is a standard generative adversarial network taken from Philip Paquette’s blog, the following figure illustrates it’s architecture.
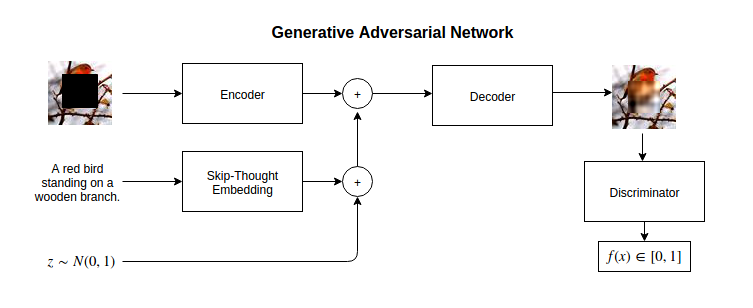
Fig. 1. Visual representation of the GAN framework. Code is available here.
The generator is composed of an encoder which is a smaller version of the SqueezeNet architecture [3] and a decoder made up of multiple strided transposed convolutions while the discriminator is a simple encoder.
Both the generator and discriminator were trained simultaneously for 100 epochs using Adam optimizer, dropout was added at the middle of training and I also used feature matching to the generator’s objective which really helped it learn better reconstruction features.
Data Augmentation
I did not perform much data augmentation, images were simply randomly rotated once in a while, from my “experiments”, it is not clear at all if this trick helped the model generate better images.
Caption Encoding
I decided to encode the captions using a pretrained skip-thought model [6], this network learns, in an unsupervised way, a vector representation that preserves the syntactic and semantic properties of the sentences it encodes.
Boundary Equilibrium Generative Adversarial Network
In the BEGAN framework, the discriminator is an autoencoder. The objective function is a minimax game, but unlike standard GANs, the generator tries to minimize the reconstruction error of the images it provides to the discriminator while the discriminator wants to simultaneously maximize this error and minimize the reconstruction error of the true images. The following figure gives a summary of this architecture.
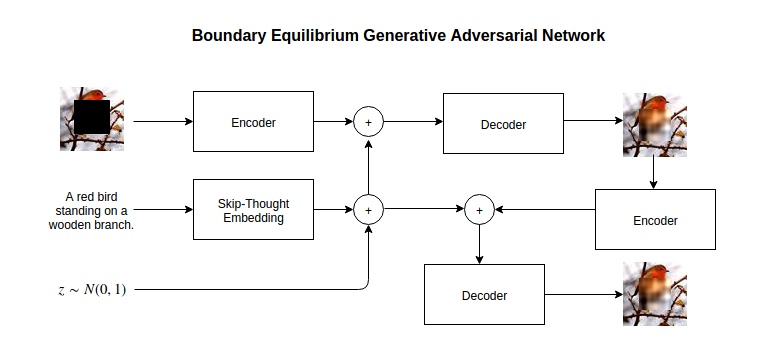 Fig. 2. Visual representation of the BEGAN framework. Code is
available here.
Fig. 2. Visual representation of the BEGAN framework. Code is
available here.
The BEGAN model is based on the assumption that the reconstruction error of an autoencoder follows a normal distribution, when it is the case we can compute the Wasserstein distance between them relatively easily.
Let $ L(v) = |v - D(v)| $ be the reconstruction error of some image $ v $, if $ L(X) \sim N(m_1, C_1) $ and $ L(G(z)) \sim N(m_2, C_2) $ then the Wasserstein distance between the true image reconstruction and the fake image reconstruction is given by
Therefore, if $ \dfrac{C_1 + C_2 - 2 \sqrt{C_1 C_2}}{\parallel m_1 - m_2 \parallel^2} $ is constant or monotonically increasing $ W(L(X), L(G(z))^2 \propto \parallel m_1 - m_2 \parallel^2 $, thus, we can maximize this equation by minimizing $m_1$ (which is equivalent to autoencoding the real images) and maximizing $m_2$.
The BEGAN objective is then given by:
Which is almost the same as the regular GAN (and WGAN), note that we don’t need the Lipschitz conditions like in Wasserstein GAN [4], therefore, we can train the generator and discriminator simultaneously, we recover the ability to use optimizers with momentum and we don’t have to clip the weights.
Training a BEGAN resulted in many failed attempts so I decided to compile a small list of what worked best for me:
- No batchnorm in the encoders
- No ReLU/Leaky ReLU activation, exponential linear unit (ELU) seemed to work better
- No activation function in the decoders output; instead clip the values between [-1, 1]
- Do not use an autoencoder with too big capacity (e.g. SqueezeNet) for the discriminator
- Penalizing the generator with the L2 distance between the generated samples and the true images really helped stabilize training but resulted in square artefacts. (This one significantly helped when both the generator and discriminator had similar capacity)
- Using SqueezeNet as the encoder for the generator achieved better results than using the same model as the discriminator, also, it did not require the need of any kind of penalty on the loss to keep training stable. (unfortunately, I did not have time to test if adding it would improve my results)
Convergence Measure
One of the main frustration I had with generative adversarial networks is that the loss of it’s objective function does not mean anything in terms of image quality (or even convergence), therefore, training is usually very hard and unstable.
In the BEGAN paper the authors come up with a convergence measure $ M_{global} = L(X) + \mid \gamma L(X) - L(G(z)) \mid $ where $\gamma$ is a hyperparameter between zero and one. The following plot shows that this convergence measure is well correlated with image quality, we can also notice that convergence is quite quick.
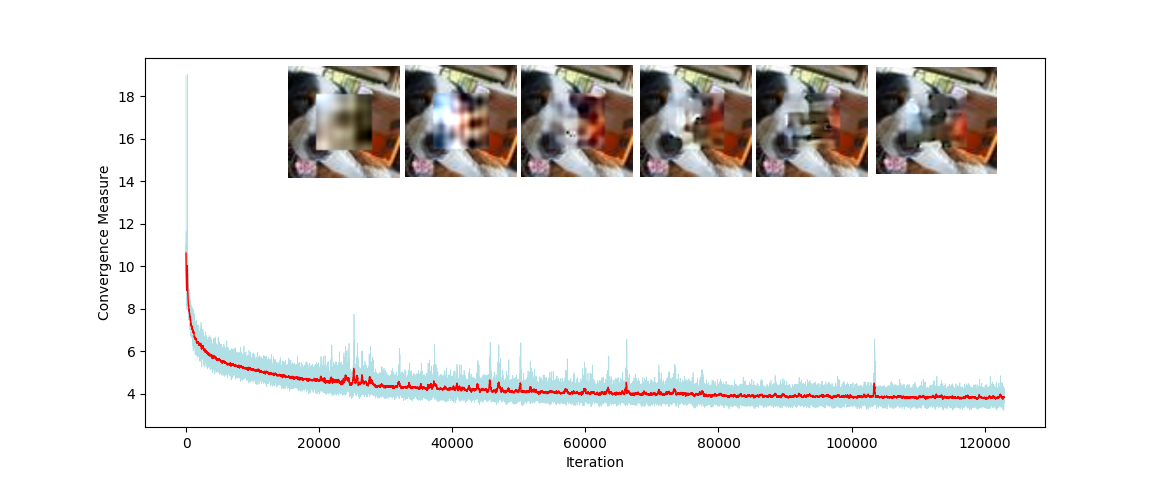
Fig. 3. Convergence measure versus number of iteration.
Results
In most cases, the pictures generated by my GAN and BEGAN were mostly of the same quality, however, when it came to generating any kind of faces, the BEGAN model outplayed the GAN, from the experiments I ran, I felt that the hardest pictures to generate were faces and especially when something covered it slightly e.g. a phone or a toothbrush (in this case, both approach failed miserably).

Fig. 4. GAN vs BEGAN.
In the following figure, I inserted some of the best pictures my model reconstructed. You can see that it sucessfully learned some basic things about our world such as the fact that humans have arms and that faces are composed of a pair of eyes, a nose and a mouth.

Fig. 5. Some pictures generated by the BEGAN architecture.
Experiments
To test whether the captions have an effect on the reconstructed images, most people tried to replace the embedded sentences with random noise, instead, I decided to feed the model tricky sentences that were very similar to the true one and the context of the image e.g. Replace “A bottle of wine with a red sticker” to “A bottle of wine with a blue sticker”.

While my experiments were not conclusive, I still think that this approach will work if used on a model that generates higher quality images. In the future, it would be interesting to test it on higher resolution images using a model like StackGAN [8].
References
[1] Alec Radford, Luke Metz, Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv preprint arXiv:1511.06434. 2016.
[2] David Berthelot, Thomas Schumm, Luke Metz. BEGAN: Boundary Equilibrium Generative Adversarial Networks. arXiv preprint arXiv:1703.10717. 2017.
[3] Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, Kurt Keutzer. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv preprint arXiv:1602.07360. 2016.
[4] Martin Arjovsky, Soumith Chintala, Léon Bottou. Wasserstein GAN. arXiv preprint arXiv:1701.07875. 2017.
[5] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville. Improved Training of Wasserstein GANs. arXiv preprint arXiv:1704.00028. 2017.
[6] Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler. Skip-Thought Vectors. arXiv preprint arXiv:1506.06726. 2015.
[7] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. Generative Adversarial Networks. arXiv preprint arXiv:1406.2661. 2014.
[8] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaolei Huang, Xiaogang Wang, Dimitris Metaxas. StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks. arXiv preprint arXiv:1612.03242. 2016.