Class Project: Installment 01 - Kick-Off!
In this post we provide strong evidence that auto-encoders have very poor creative skills. We develop multiple models, starting from a standard convolutional auto-encoder up to a very sophisticated 36-layer “ResNet” and run experiments that shattered our hopes of ever generating somewhat “life-like” images let alone analyzing the effect of captions with this kind of models.
While this introduction might, at first sight, seem hugely pessimistic we were able to gather important intelligence that will help us throughout this project, we also pinpoint the main flaw in our model and propose an alternative that we will explore in the following posts.
The Project in One Sentence
We are given captions associated to images where the middle region has been cropped, the goal is to regenerate these images.

The problem is ill-posed because we don’t care about an exact replica of the images; rather, we would like clear illustrations, coherent with their tags and the world as we’re used to see it (e.g. no wings on an airplane).
Before thinking about coherence between tags and images, one must first be able to generate decent quality pictures, therefore, this post and probably the next one will be dedicated to this task.
A First Model…
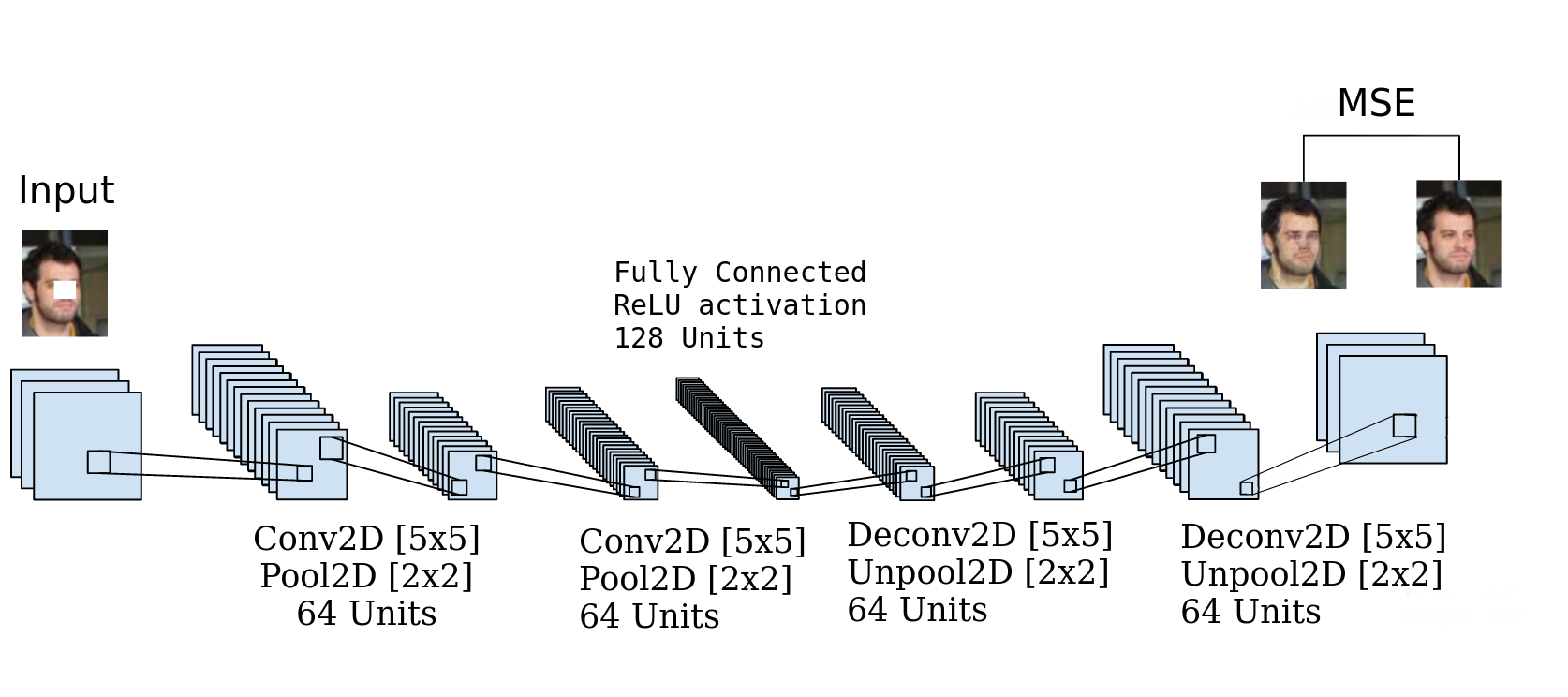
Fig. 1. Modified from [2]. Visual representation of our first model. Four-layer deep convolutional autoencoder with 128 units fully-connected layer encoder. Code is available here.
An auto-encoder seemed like a natural choice for me to starts with, in theory, it has (almost) everything you would need: An encoder network that synthesizes the information in a compact form that is decrypted by the decoder to generate a plausible middle region.
However, it has a big flaw, which resides in the way it addresses the problem by itself: by optimizing the mean squared error it learns to detect irregular patterns pixel-wise which makes it incredible at denoising [1] but terrible at creating since the latter requires a more global understanding of the picture and what it is depicting.
The following figure display a few images generated by our most basic model with different “degree” of regularization.

Fig. 2. a) No regularization. b) BatchNorm. c) BatchNorm and skip connections. d) BatchNorm, skip connections and DropOut.
We clearly see that there is absolutely (at least for me) no way of distinguishing whether regularization helped reduce image blurring; however, if it did have an effect, it was not negative.
While the effect of regularization is not obvious to the human eye, it clearly had an impact on training: The following line chart illustrate validation loss with diverse method of regularization.

Fig. 3. Validation loss for different degrees of regularization: from no regularization at all to BatchNorm, skip connections & DropOut
Surprisingly, the fully-packed regularization model never reached a level of generalization as good as the one with skip connections and DropOut, the early-stopping criteria also took much more time to fire.
We also see that regularization made the model converge deeper and much more quickly except in the case of DropOut which is odd and definitely needs more investigation (my guess is that the network is left with too few information to work with since the images were already missing 50% of their data and DropOut removed another 50%).
At this point in my analysis I felt terrible for auto-encoders and could not believe that was it - I had to give them one last shot.

Last Resort: 36-Layer Convolutional AutoEncoder with Skip Connections
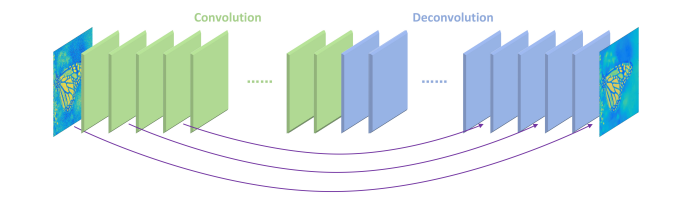
Fig. 4. Taken from [1], Deep Residual Convolutional AutoEncoder Network with 16 layers of convolution encoder & 16 layers of transposed convolution decoder. Code is available here.
This model was implemented by Mao, Shen & Yang [1], they had amazing results with denoising text-corrupted images and, for some reason, I thought this was the key to my problems - turns out I was wrong.
Below you will find the same image generated after each epoch during the training of our deep residual convolutional auto-encoder.

Fig. 5. Test Image generated at every epoch by a Deep Residual Convolutional AutoEncoder Network
As you can see it did quite better then our last model: The square artefact disappeared, my interpretation is that an autoencoder has enough capacity to fit a distribution given enough conditional information (the contour of the square), however, if not much information is available (the middle region of the images), it becomes very bad at inference (Much like us when given a task such as completing the sentence: Your name is __ __ with no previous information available).
In the next post we will take a look at some of the results I got using a generative adversarial network.